Introduction

On the official website, Kafka is described as an “open-source distributed event streaming platform”. The Apache Foundation is a nonprofit corporation created in 1999 whose objective is to support open-source projects. It provides infrastructure, tools, processes, and legal support to projects to help them develop and succeed. It is the world’s largest open source foundation and as of 2021, it supports over 300 projects totaling over 200 million lines of code.
The source code of Kafka is not only available but the protocols used by clients and servers are also documented on the official site. This allows third parties to write their own compatible clients and tools. It’s also noteworthy that the development of Kafka happens in the open. All discussions (new features, bugs, fixes, releases) happen on public mailing lists and any changes that may impact users have to be voted on by the community.
This also means Apache Kafka is not controlled by a single company that can change the terms of use, arbitrarily increase prices, or simply disappears. Instead, it is managed by an active group of diverse contributors. To date, Kafka has received contributions from over 800 different contributors. You can find the current Committer and PMC member roster for Kafka on the website: https://kafka.apache.org/committers.
Core Concepts of Apache Kafka
So how does Kafka work? Broadly, Kafka accepts streams of events written by data producers. Kafka stores record chronologically in partitions across brokers (servers); multiple brokers comprise a cluster. Each record contains information about an event and consists of a key-value pair; the timestamp and header are optional additional information. Kafka groups record into topics; data consumers get their data by subscribing to the topics they want.

Events
An event is a message with data describing the event. For example, when a new user registers with a website, the system creates a registration event, which may include the user’s name, email, password, location, and so on.
Consumers and Producers
Producer: In Kafka, a producer is an application or system that generates and sends messages to a Kafka cluster. It publishes messages to a specific Kafka topic, which is a category or feed name to which messages are organized. Producers are responsible for selecting the appropriate topic and partition to which the message should be written. They can also specify keys for the messages, which can be used for partitioning and ordering.
Consumer: A consumer is an application or system that reads and processes messages from Kafka topics. Consumers subscribe to one or more topics and consume messages from the partitions within those topics. They can read messages in real time as they arrive or consume them from a specific offset within a partition. Consumers can be part of a consumer group, where each consumer in the group reads from a subset of partitions, enabling parallel processing of messages.
Brokers and Clusters
Broker: A broker is a server instance in Kafka that handles the storage and movement of messages. It acts as a middleman between producers and consumers. Brokers are responsible for receiving messages from producers, storing them in a commit log on disk, and serving those messages to consumers when requested. They handle the replication and synchronization of data across multiple brokers to ensure fault tolerance and high availability.
Cluster: A Kafka cluster is a group of brokers working together to provide a distributed and fault-tolerant environment for messaging. A cluster typically consists of multiple broker instances running on different machines or servers. These brokers are interconnected and communicate with each other to ensure data replication and load balancing. Each broker in the cluster is assigned a unique ID and can be identified by its hostname and port number.
Clusters in Kafka offer several advantages:
Scalability: Brokers can be added or removed dynamically to increase or decrease the capacity of the cluster.
High Availability: Kafka provides replication of data across brokers, ensuring that messages are still accessible even if a broker fails.
Fault Tolerance: If a broker goes down, other brokers in the cluster take over its responsibilities, ensuring continuous operation.
Load Balancing: Kafka evenly distributes message load across brokers, ensuring efficient utilization of cluster resources.
Kafka clusters are designed to handle large-scale data processing and can support high-throughput, low-latency messaging systems. They enable the distribution and parallel processing of messages across multiple brokers, making Kafka suitable for a wide range of use cases, such as real-time data streaming, event-driven architectures, and log aggregation.
Topics
Topics is a category or feed name to which messages are published. It represents a stream of records or messages that are stored and organized in a distributed manner across Kafka brokers. Topics serve as the central unit of data organization in Kafka and allow producers to publishing messages and consumers to consume those messages.
Here are some key characteristics of topics in Kafka:
Naming: Topics are named entities within Kafka and are typically identified by a string name. For example, a topic could be named "orders," "logs," or "user events."
Partitioning: Topics are divided into partitions, which are individual ordered logs. Each partition is an ordered sequence of messages and is stored on a single broker. Partitioning allows for parallel processing and scalability, as different partitions can be consumed by different consumers concurrently.
Replication: Kafka provides the ability to replicate topic partitions across multiple brokers. Replication ensures fault tolerance, data durability, and high availability. Each partition has one leader and multiple replicas, with the leader handling read and write operations.
Message Retention: Kafka retains messages for a configurable period of time, allowing consumers to read messages at their own pace. This feature enables data replayability and provides flexibility in handling real-time and historical data processing.
Publish-Subscribe Model: Topics follow a publish-subscribe model, where producers publish messages to a topic, and consumers subscribe to topics to consume messages. Multiple producers and consumers can interact with a topic simultaneously, enabling data sharing and distribution.
Topics are a fundamental concept in Kafka and form the basis for building scalable, fault-tolerant, and real-time data processing systems. They provide a flexible and scalable architecture for handling high-throughput data streams in various use cases, such as event sourcing, log aggregation, stream processing, and more.
Partitions

Partitions are the fundamental units of data organization within a topic. Each topic in Kafka is divided into one or more partitions, and these partitions allow for scalability, parallelism, and fault tolerance in the data processing.
By using partitions, Kafka achieves scalability, fault tolerance, and efficient message processing. The number of partitions for a topic should be determined based on factors such as data volume, throughput requirements, and desired parallelism in order to optimize the system's performance.
Advantages of Apache Kafka
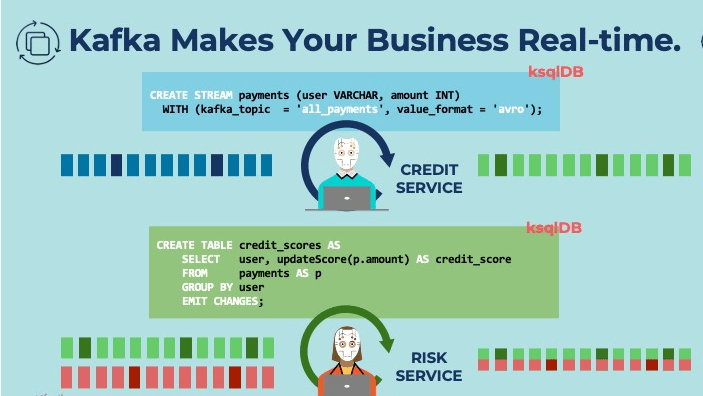
Processing Speed: Kafka implements a data processing system with brokers, topics, and APIs that outperforms both SQL and NoSQL database storage with horizontal scalability of hardware resources in multi-node clusters that can be positioned across multiple data center locations. In benchmarks, Kafka outperforms Pulsar & RabbitMQ with lower latency in delivering real-time data across streaming data architecture.
Platform Scalability: Originally, Apache Kafka was built in order to overcome the high latency associated with batch queue processing using RabbitMQ at the scale of the world’s largest websites. The differences between mean, peak, and tail latency times in event message storage systems enable or limit their real-time functionality on the basis of accuracy. Kafka’s broker, topic, and elastic multi-cluster scalability support enterprise “big data” with real-time processing with greater adoption than Hadoop.
Pre-Built Integrators: Kafka Connect offers more than 120 pre-built connectors from open-source developers, partners, and ecosystem companies. Examples include integration with Amazon S3 storage, Google BigQuery, ElasticSearch, MongoDB, Redis, Azure Cosmos DB, AEP, SAP, Splunk, and DataDog. Confluent uses converters to serialize or deserialize data in and out of Kafka architecture for advanced metrics and analytics. Programming teams can use the connector resources of Kafka Connect to accelerate application development with support for organizational requirements.
Managed Cloud: Confluent Cloud is a fully-managed Apache Kafka solution with SQL DB integration, tiered storage, and multi-cloud runtime orchestration that assists software development teams to build streaming data applications with greater efficiency. By relying on a pre-installed Kafka environment that is built on the best practices in enterprise and regularly maintained for security upgrades, business organizations can focus on building their code without the hardships of assembling a team and managing the streaming data architecture with 24/7 support over time.
Real-time Analytics: One of the most popular applications of data streaming technology is to provide real-time analytics for business logistics and scientific research at scale to organizations. The capabilities enabled by real-time stream processing cannot be matched by other systems of data storage, which has led to the widespread adoption of Apache Kafka across diverse projects with different goals, as well as to the cooperation in code development from business organizations in different sectors. Kafka delivers real-time analytics for Kubernetes with Prometheus integration.
Enterprise Security: Kafka is governed by the Apache Software Foundation, which provides the structure for peer-reviewed security across Fortune 500 companies, startups, government organizations, and other SMEs. Confluent Cloud provides software developers with a pre-configured enterprise-grade security platform that includes Role-Based Access Control (RBAC) and Secret Protection for passwords. Structured Audit Logs allow for the tracing of cloud events to enact security protocols that protect networks from scripted hacking, account penetration, and DDoS attacks.
Use Cases for Apache Kafka

Kafka for Metrics
Kafka is used for monitoring operational data by producing centralized feeds of that data. Operational data — anything from technology monitoring to security logs to supplier information to competitor tracking and more — can then be aggregated and monitored.
Kafka for Message Broker
Kafka is one of the most popular messaging technologies because it is ideal for handling large amounts of homogeneous messages, and it is the right choice for instances with high throughput. An additional part of its appeal is that it pairs well with big data systems such a Elasticsearch and Hadoop.
Kafka for Event Sourcing
Because Kafka supports the collection of large amounts of log data, it can be a crucial component of any event management system, including SIEM (Security Information Event Management).
Kafka for Commit Logs
Kafka can act as a pseudo-commit-log, using it for the replication of data between nodes and for restoring data on failed nodes. For instance, if you are tracking device data for Internet of Things (IoT) sensors and discover an issue with your database not storing all data, then you can replay data to replace the missing information in the database.
Kafka for Tracking Website Activity
Because website activity creates large amounts of data, with many messages generated for each individual user page view and activity on the page, Kafka is integral to ensuring that data is sent to and received by the relevant database(s).
How different industries solve their use cases with Kafka.
With over 1,000 Kafka use cases and counting, some common benefits are building data pipelines, leveraging real-time data streams, enabling operational metrics, and data integration across countless sources.
Today, Kafka is used by thousands of companies including over 80% of the Fortune 100. Among these are Box, Goldman Sachs, Target, Cisco, Intuit, and more. As the trusted tool for empowering and innovating companies, Kafka allows organizations to modernize their data strategies with event streaming architecture. Learn how Kafka is used by organizations in every industry - from computer software, financial services, and health care, to government and transportation.
Dream11
The Dream11 app hosts over 150 million sports fans, with 308 million RPM (about five million requests per second), and 10.56 million user concurrency. At this scale, it’s all about crunching data to get insights and offer a personalized experience. Dream11 collects billions of events and Terabytes of data per day.
.png)
Every start-up reaches a certain inflection point when your data multiples by the second and it is extremely difficult to manage such magnitudes of data inflow. Dream11 went through this phase too; hence, we returned to the drawing board and reflected on the drawbacks of operating company data across multiple tools. That’s how the idea to build our very own ‘Inhouse Analytics’ system was born.
The genesis of ‘Inhouse Analytics’ was based on three factors.
- More control over our data.
- More flexibility to meet our internal requirements at a faster pace.
- Use the data to get intelligent insights at our discretion, without relying on outsourced tools.
Goldman Sachs
Goldman Sachs, a giant in the financial services sector, developed a Core Platform to handle data which is almost around 1.5 Tb per week.
This platform uses Apache Kafka as a pub-sub messaging platform. Even though the number of data handled by Goldman Sachs is relatively smaller than that of Netflix or LinkedIn, it is still a considerable amount of data.
The key factors at Goldman Sachs were to develop a Core Platform system that could achieve a higher data loss prevention rate, easier disaster recovery, and minimize the outage time.
The other significant objectives included improving availability and enhancing transparency as these factors are essential in any financial services firm.
Goldman Sachs has achieved these objectives through the successful implementation of the Core Platform system and Apache Kafka was a key driver of this project.
Banking
The banking sector deals with a large number of scams, money laundering, and illegal payments. Apache Kafka can assist banks in effectively identifying scams and, therefore, re-establish their integrity, confirming the best safety measures for their clients.
Banks are constantly working towards an effective strategy to give their clients a wholesome experience. Kafka can be used to gather numerous forms of data and collect them to generate innovative strategies. For example, the platform can work to suit the necessities of each client, customizing their experience. It can also incorporate and handle messages in various languages without any hassle.
LinkedIn, as the main contributor to Kafka, has an internal Kafka development team that is a reliable contact point within the company for any Kafka-related support needs. Relying heavily on Apache Kafka, LinkedIn keeps internal release branches that have been branched off separate from upstream Kafka.
Kafka was originally designed to facilitate activity tracking and collect application metrics and logs on LinkedIn. Currently, messages being relayed by Kafka are divided into five main sections, namely: queueing, metrics, logs, database replication, and tracking data.
At LinkedIn, to connect the distributed stream messaging platform, Kafka, to stream processing, Samza was developed and later became an incubator project at Apache.
Real-time processing does not always have to rely on data that has been recently created. Streams can be created from historical and static data, depending on the use case. To this end, LinkedIn has developed and open-sourced Brooklin, a distributed streaming service that can consume data from diverse sources and produce streams for other applications to use.
There are numerous more tools, like Kafka Monitor and Burrow, that are actively used in LinkedIn and open-sourced for the Kafka community. This whole ecosystem shows the importance of Kafka to LinkedIn’s operations, and how dedicated they are to pushing the limits of Kafka to new horizons.
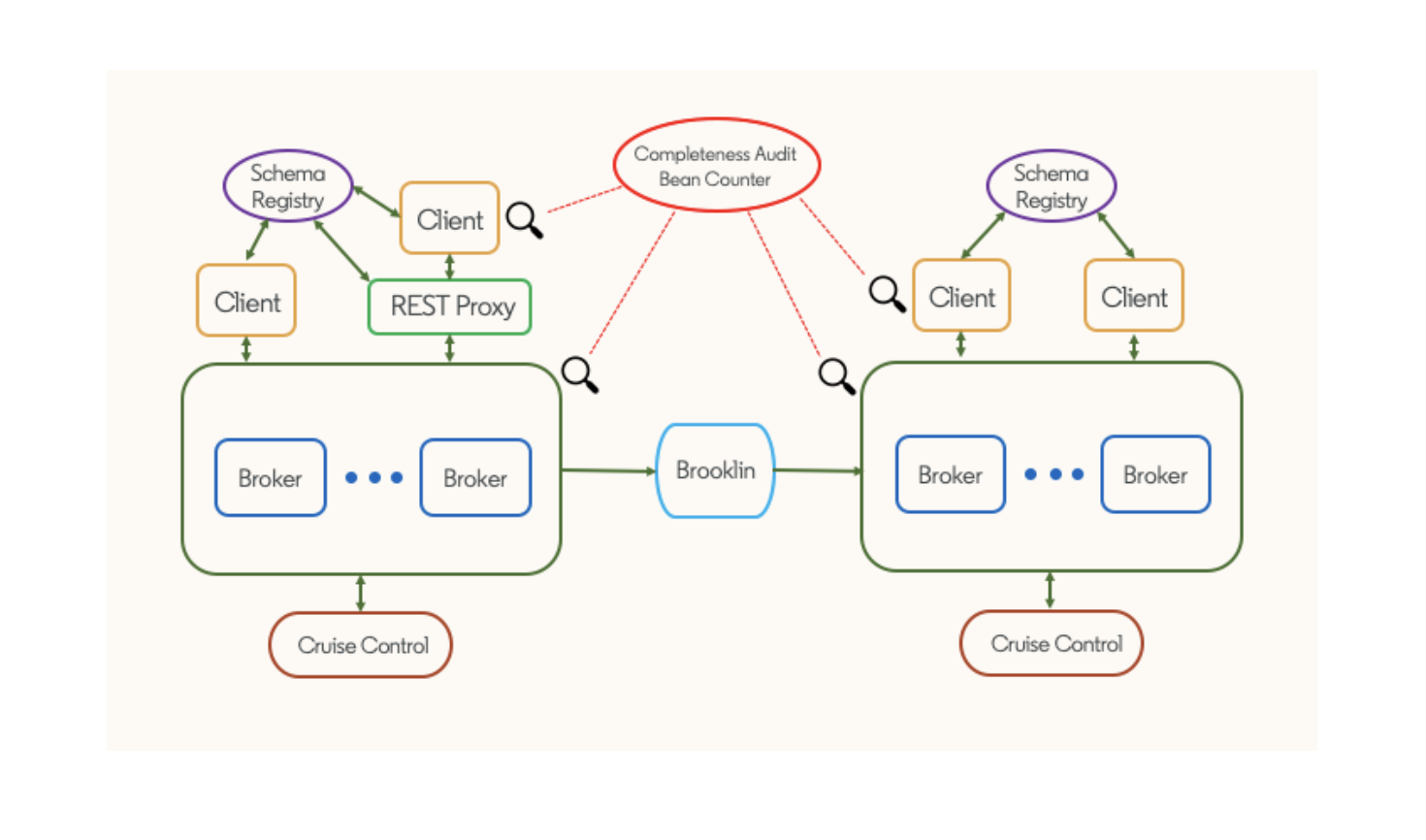
Kafka forms the backbone of LinkedIn’s stack, just as it is used by many other organizations and developers daily. LinkedIn has a great influence over Kafka as the initial developer of the tool and has helped shape the ecosystem around it.
Netflix

Netflix needs no introduction. One of the world’s most innovative and robust OTT platforms uses Apache Kafka in its keystone pipeline project to push and receive notifications.
There are two types of Kafka used by Netflix which are Fronting Kafka, used for data collection and buffering by producers, and Consumer Kafka, used for content routing to the consumers.
All of us know that the amount of data processed at Netflix is pretty huge, and Netflix uses 36 Kafka clusters (out of which 24 are Fronting Kafka and 12 are Consumer Kafka) to work on almost 700 billion instances in a day.
Netflix has achieved a data loss rate of 0.01% through this keystone pipeline project and Apache Kafka is a key driver to reduce this data loss to such a significant amount.
Netflix plans to use a 0.9.0.1 version to improve resource utilization and availability.
Spotify
Spotify, which is the world’s biggest music platform, has a huge database to maintain 200 million users and 40 million paid tracks.
To handle such a huge amount of data, Spotify used various big data analytics tools.
Apache Kafka was used to notify the users recommending the playlists and pushing targeted Ads amongst many other important features.
This initiative helped Spotify to increase its user base and become one of the market leaders in the music industry.
But, recently Spotify decided that they did not want to maintain and process all of that data so they made a switch to a Google-hosted pub-sub platform to manage the growing data.
Uber
There are a lot of parameters where a giant in the travel industry like Uber needs to have a system that is uncompromising to errors, and fault-tolerant.
Uber uses Apache Kafka to run their driver injury protection program in more than 200 cities.
Drivers registered on Uber pay a premium on every ride and this program has been working successfully due to the scalability and robustness of Apache Kafka.
It has achieved this success largely through the unblocked batch processing method, which allows the Uber engineering team to get a steady throughput.
The multiple retries have allowed the Uber team to work on the segmentation of messages to achieve real-time process updates and flexibility.
Uber is planning on introducing a framework, where they can improve the uptime, grow, scale, and facilitate the program without having to decrease the developer time with Apache Kafka.
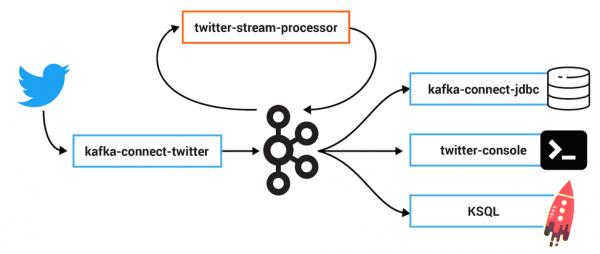
Twitter, a social media platform known for its real-time news, and story updates is now using Apache Kafka to process a huge amount of data.
Earlier, Twitter used to have their own pub-sub system EventBus to do this analysis and the data processing but looking at the benefits and the capabilities of Apache Kafka, they made the switch.
As the amount of data on Twitter is increasing with every passing day, it was more logical to use Apache Kafka instead of sticking to EventBus.
Migrating to Apache Kafka allowed them to ease input-output operations, increase bandwidth allocation, ease data replication, and have a lesser amount of cost.
New York Times

The New York Times, one of the oldest news media houses, has transformed itself to thrive in this era of digital transformation.
The use of technologies such as big data analytics is not new to this media house. Let’s take a look at how Apache Kafka transformed the New York Times’ data processing.
Whenever an article is published in NYT, it needs to be made available on all sorts of platforms and delivered to its subscribers within no time.
Earlier, NYT used to distribute the articles and allow access to the subscribers, but there were some issues such as one which prevented the users to access the previously published articles. Or the ones in which a higher level of inter-team coordination was required to maintain and segment the articles since different teams used different APIs.
To address this issue, NYT developed a project called Publishing Pipeline in which Apache Kafka is used to remove API-based issues through its log-based architecture. Since it is a pub-sub message system, it cannot only cover the data integration but also the data analytics part, unlike other log-based architecture services.
They implemented Kafka back in 2015-16 and it was a success according to them as Apache Kafka simplified the backend and front-end deployments. It also decreased the workload of the developers and helped the NYT to improve content accessibility.
Getting Started with Kafka
Now that you understand the main concepts of Kafka, it’s time to get it running. First, you need to make sure you have Java installed in your environment. You can download it from https://java.com/en/download/.
Then, you need to download a Kafka distribution from the official Kafka website. We recommend you grab the latest version. Note that different versions of Kafka may require different Java versions. The supported Java versions are listed at https://kafka.apache.org/documentation/#java. Kafka releases are built for multiple versions of Scala, for example, Kafka 3.0.0 is built for Scala 2.12 and Scala 2.13. If you already use a specific Scala version, you should pick the matching Kafka binaries, otherwise, it’s recommended to pick the latest.
Once you’ve downloaded the distribution, extract the archive.
$ : tar zxvf kafka_2.13-3.0.0.tgz

Starting Kafka
As described previously, Kafka initially required ZooKeeper in order to run. So we would first set up Zookeeper and come back to Brokers.
Kafka with Zookeeper
Before starting Kafka, you need to start ZooKeeper. Fortunately, the ZooKeeper binaries are included in the Kafka distribution so you don’t need to download or install anything else. To start ZooKeeper you need to make sure you have Java installed in your environment. You can download it from https://java.com/en/download/.
Then, you need to download a Kafka distribution from the official Kafka website at https://downloads.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgz.

Once you’ve downloaded the distribution, extract the archive by:
$ : tar zxvf kafka_2.13-3.0.0.tgz

To start ZooKeeper you run:
$ : ./bin/zookeeper-server-start.sh config/zookeeper.properties &

If ZooKeeper is successfully started, look like this:

It started on Port no: 2181

Configure Broker
As we have set up our Zookeeper we need to update the configuration file of the broker with Zookeeper IP Address with Port No and provide a unique id to each Broker.


To start Kafka on Broker :
$ : ./bin/kafka-server-start.sh config/server.properties &

This will run Kafka in the background.
To Check from the zookeeper, how many Brokers are connected :
$ : ./bin/zookeeper-shell.sh <Zookeeper IP> ls /brokers/ids

Kafdrop - Kafka WebUI with Docker
To setup WebUI for Kafka we need to have docker and provide ip of any broker to Kafdrop then, run the command :
docker run -d --rm -p 9000:9000 \
-e KAFKA_BROKERCONNECT=<Broker_IP:port> \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop

Connect Kafdrop with port no 9000 to see the WebUI

Sending and Receiving records
$ : ./bin/kafka-topics.sh --create --bootstrap-server <Broker_IP> --topic <Topics_Name> --partitions <No of Partitions> --replication-factor <No. of replication_factor>

The --partitions flag indicates how many partitions the topic will have. The --replication-factor flag indicates how many replicas will be created for each partition.
Command to list the Topics:
$ : ./bin/kafka-topics.sh --list --bootstrap-server <Broker_IP>

Let’s send a few records to your topic using the kafka-console-producer tool:
$ : ./bin/kafka-console-producer.sh --topic <Topic_Name> --bootstrap-server <Broker_IP>

$ : ./bin/kafka-console-consumer.sh --topic <Topic_Name> --bootstrap-server <Broker_IP>

Note that we added the --from-beginning flag to receive all existing records in the topic. Otherwise, by default, the consumer only receives new records.

Finally, we walked through how to start Kafka, create a topic, send and consume a record. So, let's embrace the power of Kafka, explore its endless possibilities, and revolutionize industries together. Together, we can harness the full potential of real-time data streaming, drive business growth, and shape a brighter future.
Thanks for reading...😊
Comments
Post a Comment